Model Merging and the Geometry of Optimization
TL;DR: Here I’m revisiting older notes on model merging. Gradient descent steps can be viewed as model merges, and model merges can often be interpreted as gradient steps. Making this connection explicit shows that smooth merging methods recover pre-conditioned gradient descent, while linear merging implicitly assumes a Euclidean geometry. When models are trained with different optimizers or pre-conditioners, this assumption can fail, helping explain when naive averaging works and when geometry-aware merging methods are needed.
Gradient steps as model merging
Consider a model that we wish to optimize with respect to a loss over a dataset . We will use batch gradient descent (GD) to carry out the optimization, here's the first step of this given some :
We can massage this equation to get
Thus we wrote the GD step as a linear-model-merge (often called LERP) between the original model and a unit-step local model (“local” to the dataset/batch we use, which is different from the local models from federated learning1). We expect that has a smaller loss than 2.
Local-model substitution: Using and (or ) as the models in a merging method.
It’s reasonable to try to work backwards from a model merging method to recover an optimization method by using the local-model substitution discussed here to see what optimization methods pop out. For example,
- In the single-task case, TIES3 reduces to sparsified (top-k) gradient descent.
- For small , a SLERP-merge of and is behaving like regular gradient descent.
For smooth model-merging methods, the substitution never gives surprising results, in some sense:
Lemma 1 (Smooth merging functions recover GD steps with small step-size)
Let be a “merging” function, mapping , and assume:
Consistency: for all ,
Jacobian at the diagonal: the partial derivative w.r.t. the second argument exists and
for some matrix .
Define the update
Then, as ,
So a smooth merging function recovers a pre-conditioned GD method in the small limit.
Proof
Since is , we can Taylor expand in the second argument around (i.e., around ):
Using the assumptions and , we obtain
which concludes the proof.
When , we have , so the two “models” being merged are extremely close in parameter space. This regime is not representative of most practical model merging settings, where models are typically separated by many optimization steps.
Next we look at the opposite direction: from model merging to gradient steps.
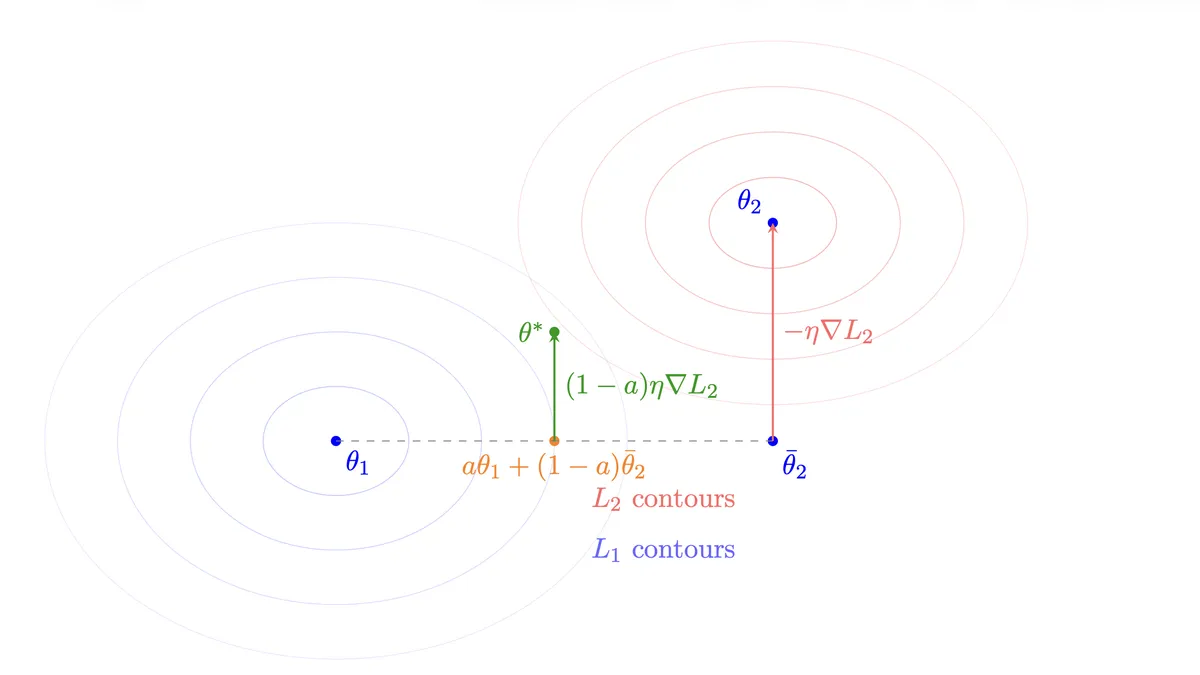
Linear model merging as gradient steps
Consider two models and derived from a common initialization and optimized on different loss functions and respectively using gradient descent. Therefore, we get that, for , there exists a point and learning rate such that:
Those4 have to exist as they represent the last optimization step that resulted in .
Now, for a linear model-merge with interpolation parameter :
By substituting the gradient descent representation of :
Thus the merged model can be seen as a gradient descent step where:
- The starting point is the weighted average
- The step is in the direction of
- The effective learning rate is
So linear model merging is taking a partial gradient step from an interpolated position in parameter space, with the size of the step modulated by the merge coefficient .
Riemannian geometry and model merging
Lemma 1 says that smooth model merging methods, when used with the local-model substitution we discussed earlier, behave like pre-conditioned gradient descent. In light of all this, I think we can sense-check linear model merging when used with models that optimize under different optimizers.
Suppose we have representing the model parameters of two models trained with the losses and different optimization schemes, which we will assume are:
where and are pre-conditioners, , symmetric and positive-definite, , and we assume those are converging to and .
Without getting too deeply into Riemannian geometry, the existence of pre-conditioner in gradient descent (GD) means that each corresponding GD makes steps in a geometry with metric . We can then measure the distance of a from by using
which uses the metric that each GD is optimizing in. For example, if , the corresponding would penalize harshly deviations in the second dimension.
Given this, we would want a successful merge to be close to
It turns out that we can find exactly as everything is linear:
Toy example
Now, we assume and , and .
- Linear merge:
- Optimal merge:
We can also compute the errors according to .
and
As expected, the optimal merge has much smaller error compared to the naive merge because the naive merge does not account for the geometry.
This toy example illustrates a general failure mode of naive linear merging. When models are trained with different pre-conditioners (or even different optimizers!), they implicitly optimize under different geometries. Linear interpolation assumes a shared Euclidean geometry and therefore computes the wrong midpoint. The resulting merged model can be arbitrarily far from optimal5.
Notably, several existing merging methods can be understood precisely as attempts to respect this geometry, e.g., Fisher merging6, Ties-merging, etc.
Footnotes
Sebastian U. Stich. Local sgd converges fast and communicates little, 2019. URL https://arxiv.org/abs/1805.09767.↩
From this POV, the optimization can be seen as an incremental merge of multiple local models with the initial (randomly initialized) , that is: which in turn is like an exponential moving average (EMA) of models, representing the -th batch (it's not exactly an EMA because the term depends on the current state).↩
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging:Resolving interference when merging models. Advances in Neural Information Processing Systems, 36, 2024.↩
There's nothing special about using . We can make the same argument w.r.t .↩
To be clear, a failure to decrease does not in general imply a failure to decrease the combined loss . Such an implication only holds in a local regime, when we are sufficiently close to , the losses are smooth, and the metric approximates the local Hessian.↩
Matena, M. S., & Raffel, C. A. (2022). Merging models with fisher-weighted averaging. Advances in Neural Information Processing Systems, 35, 17703-17716.↩