LLMs and Dynamic Cheatsheets: Learning from Experience
Since the automatic-statistician1, I've found that systems that can probe an environment, make hypotheses and plan experiments, can make some interesting (if trivial) discoveries. LLM agents are quickly becoming important components of such systems, proposing solutions to problems from geometry2 to open-ended questions from science3.
Typically, LLMs accumulate knowledge through their chat history. Recent implementations, like ChatGPT and Gemini, allow users to record persistent facts (which are likely appended to the prompt per call). In casual chats, most information from history can probably be summarized into a few facts that the LLM can use later (instead of having to attend to everything).
I was experimenting with something along these lines, a short-term memory for an LLM, which looks a bit like the work from Suzgun4, M., et al, 2025, “Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory.”.
We want an LLM agent to work on a task while accumulating a list of facts, for example:
Round 30:
thoughts:
* Right deduction: Opponent plays scissors after Player A plays paper.
* Right deduction: Opponent plays scissors after Player A plays rock.
* Wrong deduction: Opponent is likely to continue with the same move if it results in a tie.
* Wrong deduction: Opponent may be trying to mirror my moves.
* Wrong deduction: Opponent switches to rock after a tie.
* Wrong deduction: Opponent favors rock.
* Wrong deduction: The opponent's strategy is to play rock after Player A plays rock.
* Hypothesis: Opponent is largely sticking to a pre-determined sequence, with the "scissors after paper" and "scissors after rock" being the only consistently observed patterns.
* Hypothesis: The opponent's deterministic strategy might be based on a longer sequence of moves that is not yet fully apparent.
All experiments use gemini-flash, see for example: gist
An RPS example
The goal here was to have an agent that can, through repeated play, try out different hypotheses and learn about its opponent to gain an edge over repeated games of rock-paper-scissors.
For the LLM player, I defined two different dspy signatures called “PlayerA” and “SummariseThoughts”.
First, PlayerA, which has the prompt:
You are Player A in a game of rock-paper-scissors against a deterministic opponent. Your goal is to discover the opponent's strategy and win more rounds than you lose.
# Information Provided:
- Opponent Strategy: The opponent follows a fixed, non-random strategy and will not change it.
- Your Knowledge ("what_you_know_thus_far"): This summarizes your current understanding, including:
* "Right deduction": Strategies/patterns you have confirmed with high confidence.
* "Wrong deduction": Strategies/patterns you have refuted with high confidence.
* "Hypothesis": Potential strategies/patterns you are currently investigating.
- Game History ("previous_moves"): A list showing all past moves (e.g., "You:rock", "opponent:scissors").
# Your Task: Decide the best move for the *next* round.
# Decision Process:
1. Prioritize "Right deductions": If a 'Right deduction' clearly dictates a winning move based on the predicted opponent move, play that winning move. Explain this reasoning.
2. Consider "Wrong deductions": Ensure your planned move doesn't rely on a 'Wrong deduction'.
3. Test Hypotheses: If no 'Right deduction' provides a clear best move, review the active "Hypothesis" list. Select a move that will best *test* the most promising or uncertain hypothesis. State which hypothesis you are testing and why your chosen move helps test it.
4. Default/Exploration: If no deductions or testable hypotheses guide your decision, make a move (e.g., randomly, or trying to counter the opponent's last move) aimed at gathering more information. Explain your exploratory reasoning.
- Always comment on the outcome of the *previous* round in your rationale, referencing your deductions/hypotheses from that round.
- Use all available information to make your decision.
with fields
what_you_know_thus_far = dspy.InputField(
description="A structured summary (including deductions and hypotheses) of what you knew before this round."
)
previous_moves: list = dspy.InputField(
description="List of previous moves in this game (e.g., ['You:rock', 'opponent:scissors', ...]).",
)
move: str = dspy.OutputField(
description="Your chosen move for the next round: 'rock', 'paper', or 'scissors'.",
)
So PlayerA will review not just the past history of moves, but a list of hypotheses and deductions. Its primary goal is to win the game, with a close secondary goal of learning generalizable facts that can help.
To curate the accumulated knowledge, we use the OrganiseThoughts step:
You are a thought-organiser and strategist analysing a Rock-Paper-Scissors game. Your goal is to maintain and refine a list of deductions and hypotheses about the opponent's deterministic strategy based on the game history and the reasoning ('rationale') behind the last move made by Player A.
# Input:
- rationale: Player A's reasoning for their *last* move.
- history: The full sequence of moves made by both players so far.
- thoughts: The list of deductions and hypotheses from the *previous* round.
# Your Task: Update the 'thoughts' list for the *next* round.
# Process:
1. Review Existing Deductions and Hypotheses:
- Carefully examine *every* existing "Right deduction", "Wrong deduction", and "Hypothesis" from the previous 'thoughts' list against the *entire* game 'history'.
- **Validation Rule:** If a hypothesis has correctly predicted the opponent's move in the last, say, 3 *consecutive* times it was applicable/testable, upgrade it to "Right deduction: <summary>".
- **Invalidation Rule:** If a hypothesis or even a previous "Right deduction" is clearly contradicted by the last 3 relevant rounds of 'history', downgrade/change it to "Wrong deduction: <summary>". Be prepared to correct previous mistakes.
- **Keep Consistent:** If a deduction (right or wrong) remains consistent with recent history, keep it as is. If a hypothesis is neither strongly confirmed nor refuted, keep it as "Hypothesis: <summary>".
-
2. Generate New Hypotheses:
- Based on the 'rationale' of the last move and the overall 'history', are there *new* potential patterns or strategies the opponent might be using that aren't covered yet?
- Formulate these as concise "Hypothesis: <new hypothesis>".
- Hypotheses should aim to explain the opponent's behaviour and be testable in future rounds.
3. Consolidate and Format:
- Remove redundant or clearly invalidated thoughts.
- If multiple hypotheses seem related, try to consolidate them if possible.
- Present the updated list clearly, grouping by "Right deduction", "Wrong deduction", and "Hypothesis".
# Output Format:
Return the updated thoughts as a bullet point list, like:
* Right deduction: Opponent plays the move that beats their own previous move.
* Wrong deduction: Opponent mirrors Player A's moves.
* Hypothesis: Opponent might switch strategy after 3 consecutive losses.
* Hypothesis: Opponent favors 'rock' after a tie.
The input and output for this step are defined by the following signature:
rationale: str = dspy.InputField(
description="Rationale provided by Player A for their most recent move.",
)
history: list = dspy.InputField(
description="Complete history of moves in the game.",
)
thoughts: str = dspy.InputField(
description="Bulleted list of deductions and hypotheses from the previous round.",
)
summary: str = dspy.OutputField(
description="Revised bullet point list of deductions and hypotheses for the next round.",
)
A round for playerA starts with picking a move given the past history and the collection of thoughts. The player may decide to pick a winning move or run an experiment to collect more knowledge. Then the thought organizer is run to clean up the knowledge up to this point.
We hope that over many games, PlayerA will be able to deduce enough info about PlayerB to win most games.
To keep things simple, we use a simple reactive strategy.
def PlayerB(previous_moves: list[str]) -> str:
if not previous_moves:
return "rock"
if previous_moves[-1] == "opponent:scissors":
return "paper"
elif previous_moves[-1] == "opponent:rock":
return "rock"
return "scissors"
We run 30 rounds of games and inspect what PlayerA has learned:
Round 30:
thoughts:
* Right deduction: Opponent plays scissors after Player A plays paper.
* Right deduction: Opponent plays scissors after Player A plays rock.
* Wrong deduction: Opponent is likely to continue with the same move if it results in a tie.
* Wrong deduction: Opponent may be trying to mirror my moves.
* Wrong deduction: Opponent switches to rock after a tie.
* Wrong deduction: Opponent favors rock.
* Wrong deduction: The opponent's strategy is to play rock after Player A plays rock.
* Hypothesis: Opponent is largely sticking to a pre-determined sequence, with the "scissors after paper" and "scissors after rock" being the only consistently observed patterns.
* Hypothesis: The opponent's deterministic strategy might be based on a longer sequence of moves that is not yet fully apparent.
Looks like the player was able to extract some facts, although the second deduction is incorrect.
With this approach, PlayerA wins most games (although it is an LLM against a simple reactive strategy).
Function Guessing
In this game, we first pick a function to guess, e.g., cubic, exponential, etc. Then playerA can pick different values and try to guess the form of the function; one new value is picked per round and then we again pass the rationale through a thought-organizer to distill a few facts.
Quadratic
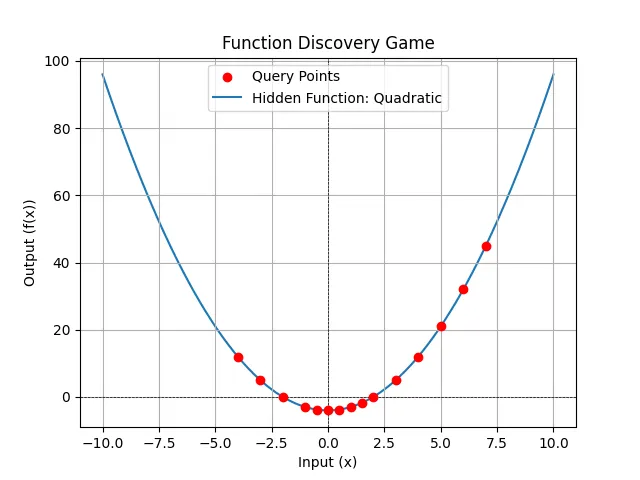
I’ll share a gist with the code, so instead here’s what we learn after a few rounds of trying to guess x**2 - 4
Current Knowledge:
* Confirmed property: f(0) = -4.
* Confirmed property: The function is quadratic, specifically f(x) = x^2 - 4. This is confirmed by the points (0, -4), (1, -3), (2, 0), (3, 5), (-1, -3), (-2, 0), (4, 12), (-3, 5), (0.5, -3.75), (-0.5, -3.75), (1.5, -1.75), (-4, 12), (5, 21), and (6, 32).
* Ruled-out property: The function is not linear.
* Hypothesis: The function exists and maps real numbers to real numbers.
Prober's Reasoning:
The query history and confirmed properties strongly suggest that the function is f(x) = x^2 - 4. I have tested several positive and negative values, including integers and non-integers. The results consistently match the expected output of the quadratic function. There is no need to query further.
If you want to see the points:
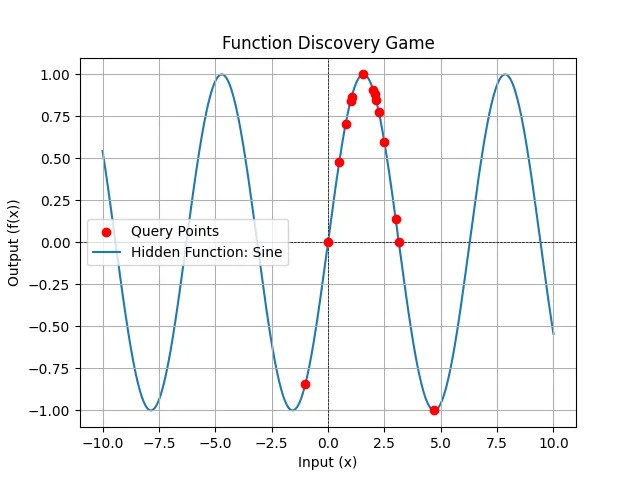
sin(x)
For , the knowledge stored by the end of the run:
* Confirmed property: f(0) = 0.
* Confirmed property: The function is odd, since f(-x) = -f(x). Evidenced by f(1) = 0.8415, f(-1) = -0.8415.
* Confirmed property: f(pi) = 0.
* Confirmed property: f(pi/2) = 1.
* Confirmed property: f(3*pi/2) = -1.
* Confirmed property: f(pi/4) = 0.7071.
* Confirmed property: f(pi/3) = 0.866.
* Confirmed property: The function is sin(x).
* Ruled-out property: The function is not linear.
* Hypothesis: The function exists and maps real numbers to real numbers (or NaN/inf).
* Hypothesis: The function might be a polynomial with a root at x=0. (Although sin(x) can be represented as a polynomial via Taylor series, this is not a simple polynomial).
* Hypothesis: The function is increasing around x=0.
* Hypothesis: The function's rate of increase is decreasing between x=0 and x=2.
* Hypothesis: The function is not always concave down for x > 0, since it decreases between x=2 and x=3.
* Confirmed property: The function has a local maximum between x=2 and x=3.
* Confirmed property: The local maximum is between x=2 and x=2.0625.
We can try as a more challenging example (both a polynomial and an oscillatory element).
After 30 rounds of playing, here’s all of the knowledge the player discovered:
Current Knowledge:
* Confirmed property: f(0) = 0.
* Confirmed property: f(1) = 0.
* Confirmed property: f(2) = 0.
* Confirmed property: f(3) = 0.
* Confirmed property: f(4) = 0.
* Confirmed property: f(5) = 0.
* Confirmed property: f(6) = 0.
* Confirmed property: f(7) = 0.
* Confirmed property: f(8) = 0.
* Confirmed property: f(9) = 0.
* Confirmed property: f(-1) = 0.
* Confirmed property: f(10) = 0.
* Confirmed property: f(11) = 0.
* Confirmed property: The function has roots at x = -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 and 11.
* Ruled-out property: The function is symmetric around x = 2.5, since f(1.5) = -1.5 and f(3.5) = -3.5.
* Hypothesis: The function exists and maps real numbers to real numbers (or NaN/inf).
* Hypothesis: The function has a local maximum between x=0 and x=1. The maximum is between x=0.625 and x=0.6875. f(0.65625) = 0.5788 is the highest value found so far in this interval.
* Hypothesis: The function has a local minimum between x=1 and x=2. The minimum is between x=1.125 and x=1.5. f(1.125) = -0.4305 and f(1.5) = -1.5.
* Hypothesis: The function has a local maximum between x=2 and x=3. f(2.25) = 1.591.
* Hypothesis: The function has a local minimum between x=3 and x=4. f(3.25) = -2.2981 and f(3.5) = -3.5.
* Hypothesis: The function has a local minimum between x=5 and x=6. f(5.5) = -5.5.
* Hypothesis: The function has a local maximum between x=6 and x=7. f(6.5) = 6.5.
* Hypothesis: The function has a local minimum between x=7 and x=8. f(7.5) = -7.5.
* Hypothesis: The function is a polynomial.
* Confirmed property: The polynomial degree is at least 13.
* Hypothesis: The function has a local minimum between x=8 and x=9. f(9.5) = -9.5.
* Hypothesis: The function alternates between positive and negative values between its roots.
And the points are:
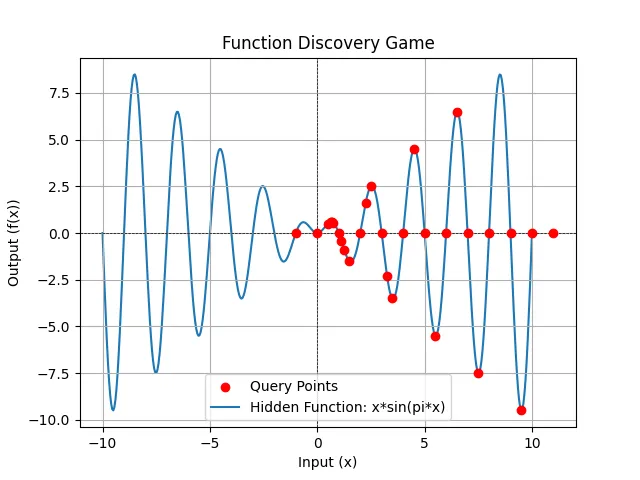
There is something quite interesting about the sampling here, targeting local minima and maxima as well as roots.
https://www.automaticstatistician.com/about/↩
https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/↩
https://sakana.ai/ai-scientist/↩
Suzgun, M., Yuksekgonul, M., Bianchi, F., Jurafsky, D. and Zou, J., 2025. Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory. arXiv preprint arXiv:2504.07952.↩