LLM agents and chess puzzles
We start from a chess puzzle, like mate in two. We would like an LLM agent to play against an opponent that makes random valid moves (let's call this player “Rando”). The agent will have a budget of k moves and needs to checkmate the opponent in those k moves (or fewer, if possible). The code is here if you want to take a look.
Chess is a favorite of LLM researchers, from showing that GPT-3.51 can play chess at a good level2 to even looking at the internal representations of models trained on millions of chess games3 (and discovering they are not trivial!). There’s even a leaderboard of LLMs against the Rando4 (and let's not forget about the Chess LLM Arena5, which we built with Maxime).
I'm using pydantic-ai for the agent scaffolding and openrouter to get access to a claude-3-7-sonnet-20250219. This agent will take as input a FEN string describing a puzzle as well as a move budget, . Then it will battle against Rando, its goal being to wrap up the game in at most moves.
Why Rando and not the best of Stockfish?
It just makes it a bit easier on the LLM. Typically winning hard positions requires thinking a deeply about the next move.
Also most chess puzzles are on the internet along with their solutions. Having Rando will keep things fresh for the LLM and evaluate whether it can keep focus throughout the game.
Finally, a good mate-in-k puzzle requires exactly k moves when the opponent plays optimally. Against Rando, we can also measure whether agents take chances to win sooner than the k move limit.
Learnings (most of which apply to any agent)
- “Perception should not confuse cognition” – Prof. Manuela Veloso.
- Use local models to test that the pipeline works correctly; you don't want to be paying
$$$to debug simple errors. - Keep feedback cycles short: if you want an agent that can play an n-moves game, iterate on one or two moves at a time.
- Set up some metrics and track them: for example, I wanted my agent to try up to times to find a good move and improve on past guesses. By scoring the move against stockfish’s best move, we get clear signal of progress (even for one move out of the of a game). Every variable and metric was auto-logged in MLflow and Logfire.
First try
Let’s see how well Claude can do against Rando if all we give is a standard COT prompt.
Your task is to make a plan to win a chess game against an opponent in a specified number of moves. You play as white and your opponent plays as black.
# Input
- FEN
- Legal moves
- Moves left
- Additional instructions, if any. (pay attention to them if they exist).
# Instructions:
1. Write a step-by-step plan as a list of moves (UCI), with reasoning for each step.
2. Analyze Black's best defenses.
3. Choose your next move from the legal moves.
# Output format
reasoning: (all your thinking and analysis)
move: (your next move in UCI format)
This is a minimal prompt on purpose; one of our goals is to optimize it.
To make it easier to focus on the game, we append this to the end of the prompt at the beginning of every round:
##### CHESS GAME ####
FEN: <board-game-in-FEN>
LEGAL MOVES: <legal-moves>
REMAINING MOVES: <some-int>
###########################
Here's a FEN which has a mate in two moves (can you find it?):
r2qk2r/pb4pp/1n2Pb2/2B2Q2/p1p5/2P5/2B2PPP/RN2R1K1 w - - 1 0
By the way, this FEN describes the board state. Left-to-right corresponds to top-to-bottom of the board. r2qk2r is read like “Rook, 2 empty spaces, Queen, Black King (k), 2 empty spaces, Rook”, and so on. Lowercase letter are for black, uppercase are for white.
Here's how the agent (white) plays:
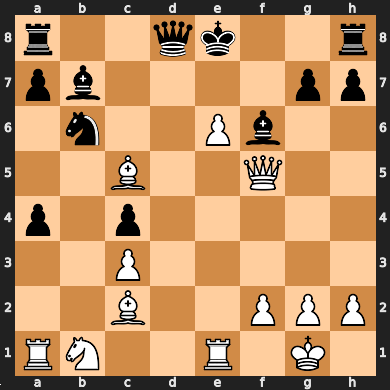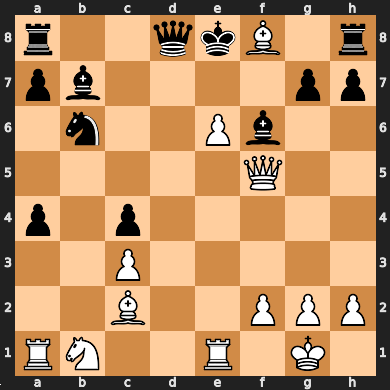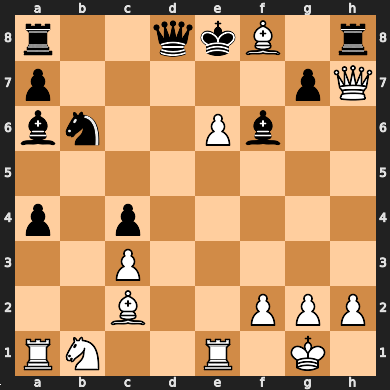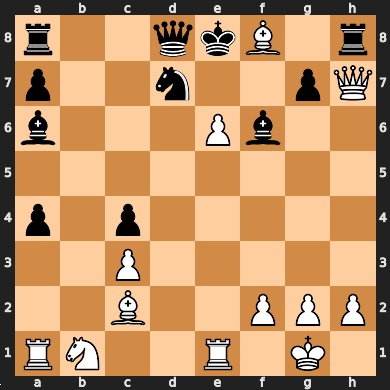
Ouch! We want the agent to plan towards a checkmate in two moves, yet in the gif we see it sacrifice pieces left and right. As we are asking for reasoning, we can review it to see what went wrong:
Let me analyze this position carefully to find a winning plan in 2 moves.
First, I'll assess the current position:
- Material is roughly equal
- White has a strong attack with the queen on f5 and bishops on c2 and c5
- Black's king is in the center (e8) and hasn't castled
- White has a pawn on e6 threatening the f7 square
- Black's pieces seem somewhat uncoordinated
Looking for tactical opportunities, I notice several promising ideas:
1. The f7 square is a critical weakness in Black's position
2. Black's king is exposed in the center
3. The bishop on c5 is eyeing the f8 square
Let me check for immediate checkmate threats:
- Qf5-h7 doesn't lead to immediate checkmate
- Qf5-g6 threatens h7 but can be blocked
- Bc5-f8 looks very strong as it attacks the king directly
The move Bc5-f8 (c5f8) is particularly powerful because:
- It's a discovered attack with the queen on f5 now targeting the king
- It's check, forcing the king to move
- After the king moves, we can deliver checkmate on the next move
If I play **Bc5-f8+**:
- **Black's king must move to d8 (only legal move)**
- Then I can play Qf5-d7#, delivering checkmate
This is a clear 2-move checkmate sequence:
Move 1: Bc5-f8+ (forcing Ke8-d8)
Move 2: Qf5-d7#
Therefore, I'll play c5f8, which is a bishop check that forces Black's king to d8, setting up the checkmate on the next move with Qf5-d7#.
Emphasis mine. Looks like the agent misread the board and somehow assumed that moving the bishop next to the king is a check.
If we play this puzzle ten times, our agent only wins once, almost always running out of moves. :(
Setting up Claude for success
After playing a few games with different FENs and this simple prompt and reviewing the reasoning, I noticed a few weak points:
- Claude can misjudge the position, sometimes reading pieces where it would like them to be instead of where they are. For example, it would hallucinate checks where there are any.
- Claude would judge a move as good without properly thinking about the counter move of the opponent (or assuming that the countermove would be something silly). This didn’t go away even with more forceful prompting.
- Things improved somewhat by asking for Claude to generate a plan in advance, but plans still assumed that the opponent plays terribly.
My first idea was tool use. Claude is very open to using tools. In fact, given a tool called is_sequence_checkmate(moves:list[str], board_state:str), Claude found the solution to the puzzle by just spamming that tool for all legal moves per round. I guess that’s intelligent.
To mimic a human player, I removed tools and instead set up a different workflow. TL;DR: we filter the set of legal moves to a few feasible moves (after all no chess player considers all legal moves per round) and build an iterative refinement loop.
More details:
- First, for every round, I do a very quick scan with stockfish to score each legal move, then only keep the top-20 moves. I shuffle them for fairness, e.g., in case Claude is biased towards the initial moves or the final moves. For every move, I also annotate whether playing it will put the Black King in check or not. Both of those are quality-of-life improvements for Claude, making perception of the game a bit clearer, although not necessarily much easier as top-20 typically contains a few good moves and mostly bad ones.
- A random legal move is picked and a max number of tries is set, say, 3. Then Claude would have that many turns to pick a move that improves on the previous move considered.
In other words and pseudocode:
move = random_player(board_state)
feedback = ''
moves_and_scores = []
for _ in range(max_tries):
move, feedback = claude_agent(move, board_state, best_counter(move), score_move(move), feedback)
moves_and_scores.append([move, score_move(move)])
if good_enough(move):
break
return move_with_max_score(moves_and_scores)
This is essentially a self-correction loop.
Claude takes as input not just the move and board state, but also a score of the move according to Stockfish (in centipawns6) as well as the best counter move by Black (again, according to Stockfish). Feedback is text that Claude generates to criticize the previous move in light of the score and the best counter move. Feedback accumulates over the tries, so Claude has a history of the moves it tried and what were the best responses.
The feedback generated by Claude is more or less:
Your proposed move <move> is bad (score: <move-score>) because the best reply is <counter-move> by Black, which allows Black to <consequences>.
The score is numerical, but it allows Claude to know whether a move is bad, good, or neutral (and also we can exit early if Claude found a good move). It's necessary to add the score, as otherwise Claude can rationalize its bad moves (as also discussed for other LLMs in the work by Huang, J., et al.,7). The best counter move provides a source for Claude to write feedback with.
Puzzle time
Let’s see how well we do in the same puzzle8.
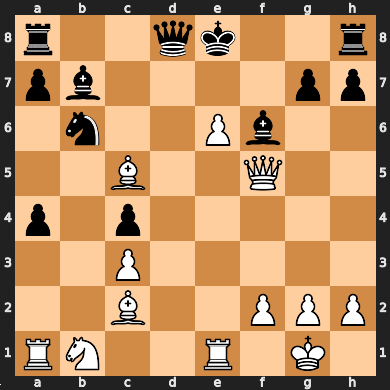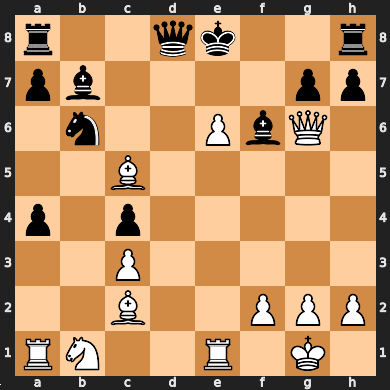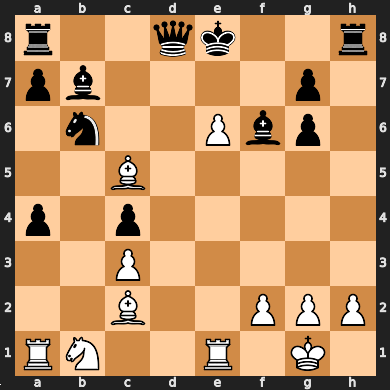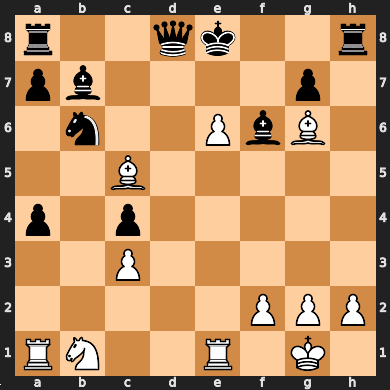
That is much better! Let’s try a harder puzzle with mate-in-3.
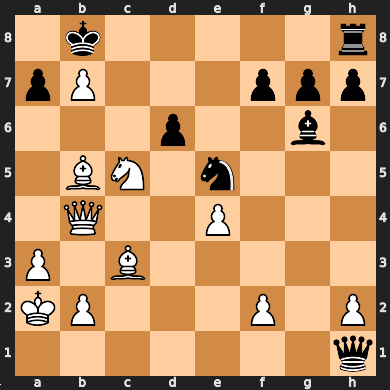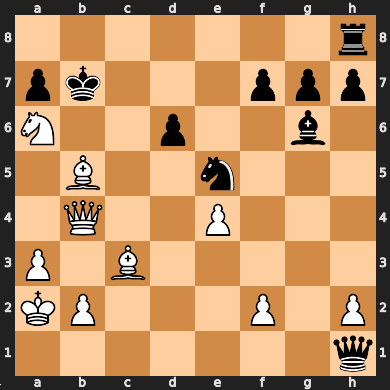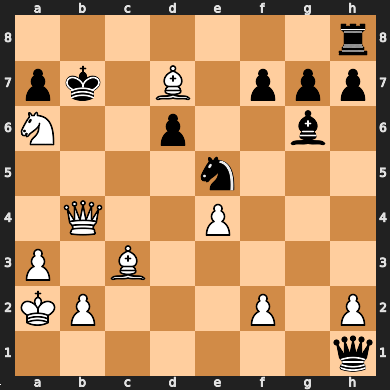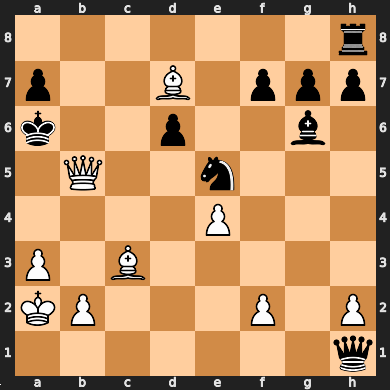
Not bad!
In both of those examples, there aren’t a lot of moves that check the black king in the first move. Let’s try a puzzle with a few more.
This next puzzle has four moves that check the black king.
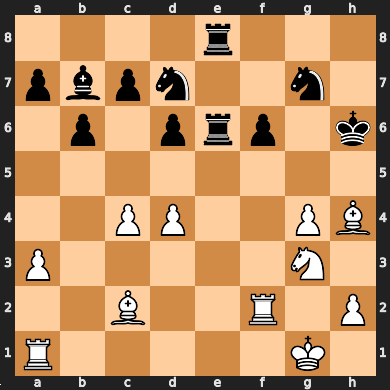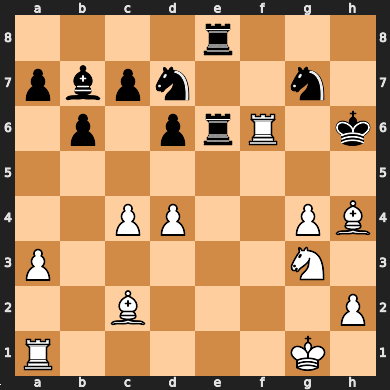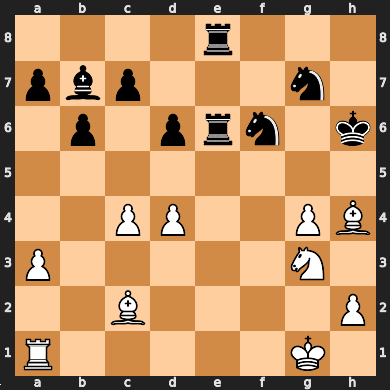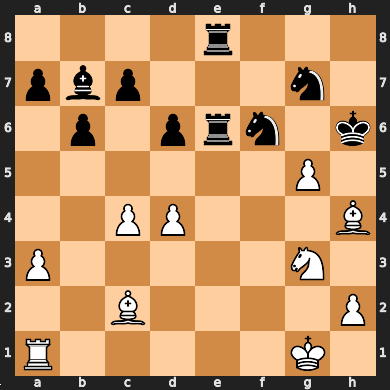
Again, the agent finds the right sequence against Rando.
How is Claude helping?!
Mainly by being more efficient than randomly sampling n moves, scoring them, and picking the best one (because we can condition on mistakes). Claude conducts its own analysis that is prone to errors, but also intuitive, and Stockfish (which doesn’t make positional mistakes) evaluates the moves a bit deeper. Although we pick the best move according to the stockfish score, it is Claude that selects which move will be evaluated.
To see the efficiency gain, we can compare Claude against a player that samples three moves that lead to check, scores all of them with Stockfish, then picks the best for each move (let’s call this player RandomCheck). We pick three moves as that is the budget Claude has per move.
To make things interesting, we will use a FEN for mate-in-5:
6r1/p3p1rk/1p1pPp1p/q3n2R/4P3/3BR2P/PPP2QP1/7K w - - 1 0
That’s a tough puzzle!
So, I ran five games for Claude and five for RandomCheck, playing against Rando. Remember:
- Rando picks random legal moves without scoring them (one per move),
- RandomCheck picks three random check moves and then scores them and picks the best one.
| Player | Win Rate |
|---|---|
| RandomCheckPlayer | 20.0% |
| Claude | 40.0% |
| Difference | +20.0% |
So, Claude won 2/5 games and RC won 1. However, I think it’s more interesting to look at efficiency metrics: how many moves does Claude make per game and how good they are on average (in comparison to the best Stockfish move). Specifically, the score is
Move Quality Comparison (Stockfish Scores):
| Metric | Random | LLM | Difference |
|---|---|---|---|
| Avg Score/Move | -7998.52 | -4355.13 | +3643.39 |
| Avg Score/Game | -7998.52 | -6678.32 | +1320.20 |
| Positive Move Rate | 76.0% | 82.6% | +6.6% |
| Score Consistency | 0.000 | 0.000 | +0.000 |
Efficiency Comparison:
| Metric | Random | LLM | Difference |
|---|---|---|---|
| Avg Moves/Game | 5.0 | 4.6 | -0.4 |
| Total Moves Played | 25 | 23 | -2 |
Looks like Claude indeed is more efficient on this hard puzzle, picking higher quality moves per turn. Spamming checks and scoring them is not enough!
Final notes
This was a fun toy project. Claude has not been prompted to think very systematically here, just to criticize a move given its score and best countermove and then propose a new one. As such, it can solve simple puzzles but will struggle with those that need deeper thinking.
References
Karvonen, A., 2024. Emergent world models and latent variable estimation in chess-playing language models. arXiv preprint arXiv:2403.15498.↩
GitHub - maxim-saplin/llm_chess: LLM Chess - Large Language Models Competing in Chess↩
Huang, J., Chen, X., Mishra, S., Zheng, H.S., Yu, A.W., Song, X. and Zhou, D., 2023. Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798.↩
All puzzles come from “SparkChess”.↩