Lifting gradient flows
In the previous post we talked about creating attracting manifolds and how to get the corresponding vector field given a manifold. In this one, we talk about optimization.
Suppose we have for which we want to find a minimum and is sufficiently smooth. For example, we can consider
def g(x): return 0.25 * (x * x - 1.0) ** 2 + 0.18 * x
That's a simple function with two minima, one local and one global. If we use the gradient of , we can create a vector field on the curve by pointing in the opposite direction of the grad, like so:
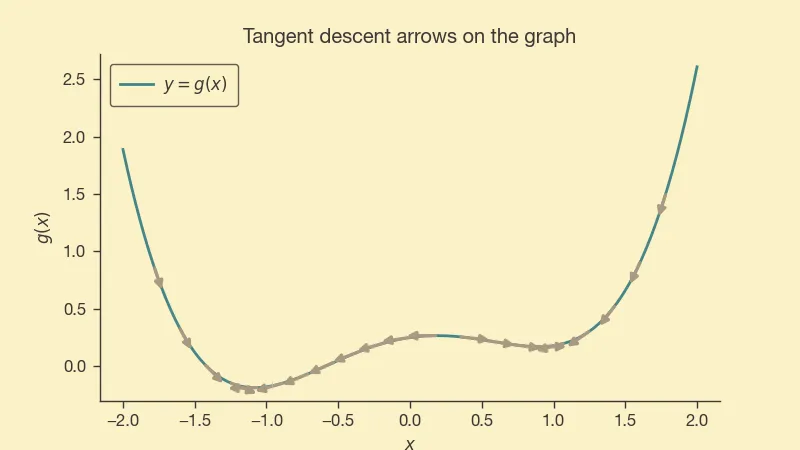
It behaves as we would expect, pointing trajectories towards the minima.
It would be fun to imagine various ways to lift the vector field from the curve to . There are infinite ways to do this.
First lift
We want to define a vector field such that trajectories moving according to it converge to the minima1 of .
To keep things simple, we will let . This way the horizontal axis behaves in the same way as if we are on the curve.
For the vertical axis, we will follow the idea of the previous post, i.e., and we want for some that we can pick. From this,
And so our differential equations are:
No matter how high is initially, the system will move towards the curve.
Here's how it looks like with :
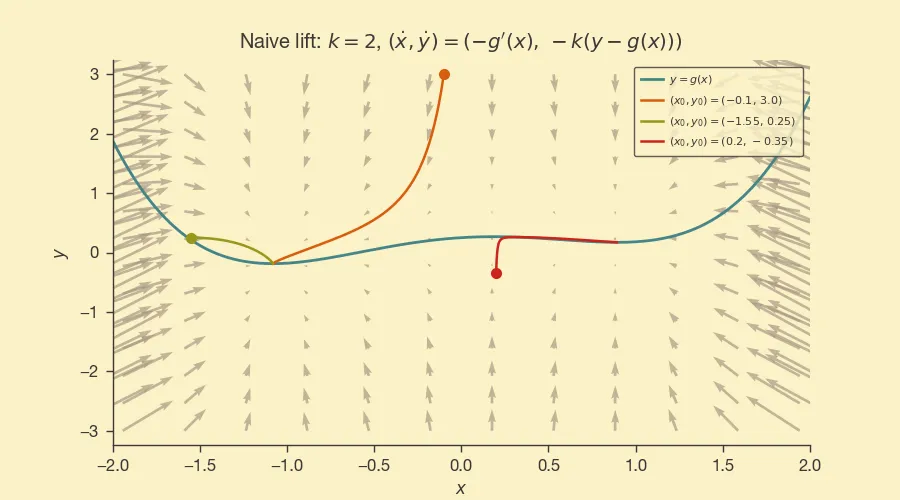
Second lift: have the dynamics of inform .
While the previous construction is simple, the axis movement is cosmetic, it is not playing any role in what we do on the axis (which is a waste and which is why we called it a “naive lift”).
As long as we pick , we will still satisfy , i.e., exponential decay of , so we have some freedom in picking .
For example, we may want the dynamics of to ignore when is large enough, e.g., pick a and set . If is large, will move towards the left even if is pointing towards the right.
We went from
to
This is what the dynamics look like in this case:
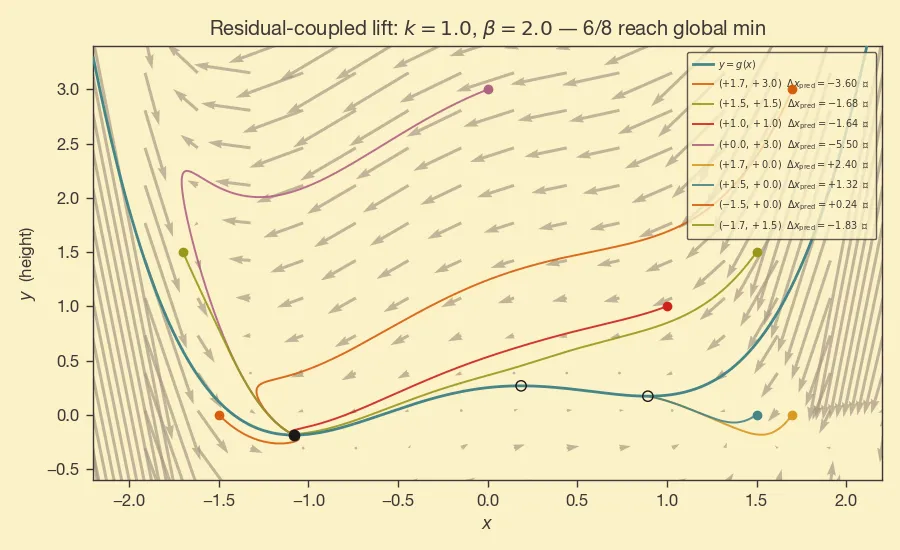
This is more interesting, but we are somewhat cheating -- the global min is to the left of the local min, and we have a method that is biased towards left movement. The behavior is clearer when the function is more complicated:
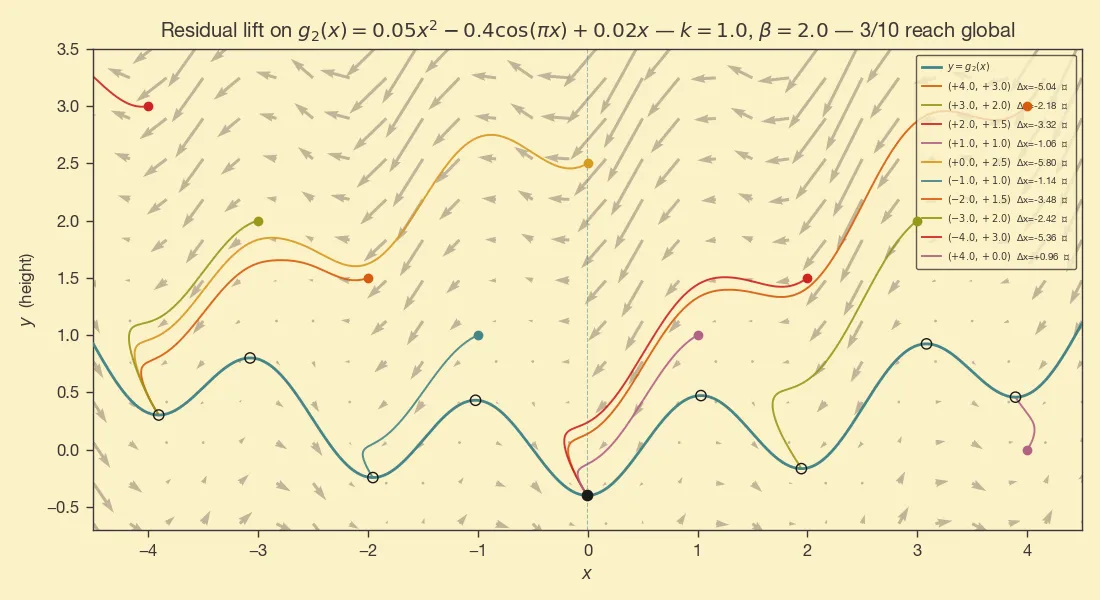
The further we are from , the more time the trajectory gets to skip a few of the basins as it moves towards the left.
Third lift
We have the freedom to pick the ODE for and get the same exponential convergence of the residual . That is, for any , we are free to define the ODE of as
We can get a few different behaviors by playing with . For example:
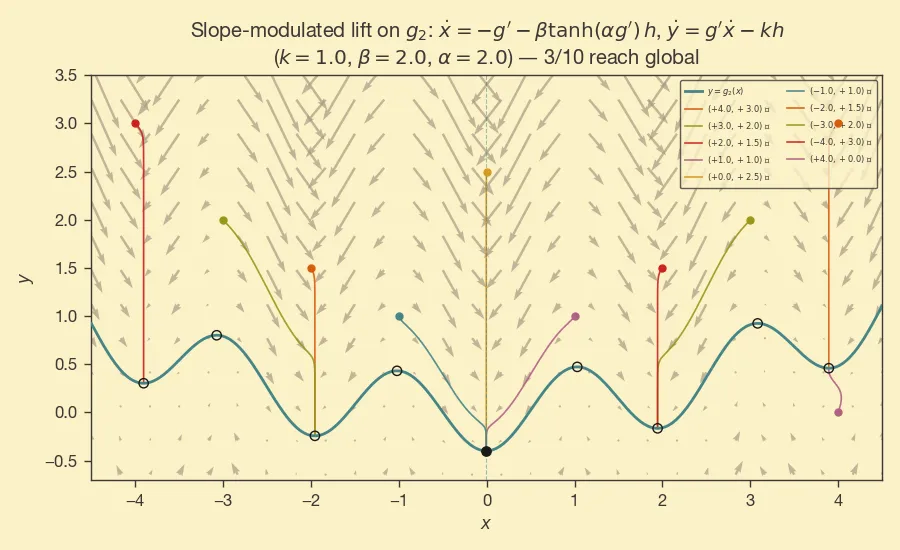
To sum up, we looked at trajectories off of that converge to minima of . There's freedom in picking the form of the ODE of , so we can get different dynamics, avoidance, etc.
Technically stationary points.↩