Greedy Coordinate Gradient
TL;DR: My notes on the “Greedy Coordinate Gradient”, first read from Zou, et al, 20231, but slightly abstracted.
Suppose we have the set , a function from sequences of elements to a vector space: , and another one , : differentiable. We want to minimize where .
First approach: Try all combinations till we find the one that minimizes . Not very promising, too many trials.
Second approach: We would love to use gradients to guide the search, but we can’t — is a discrete set! However, nobody said we cannot take a gradient of with respect to So an algorithm idea goes as follows: we start with and then compute .
From here, gives us the direction to move towards (this is an matrix), but there is a problem — the optimal direction may not be available! After all we only have the points to work with. So, to make do with what we have, we can find the direction that is most aligned with where the gradient wants to go, i.e.,
(although using cosine similarity may be a better idea -- the idea of solving the linear problem is from Frank and Wolfe2).
And if we arrange the elements of in a matrix , we can then to compute all similarities at once.
Now we can iteratively update the elements of a sequence by computing , where is equal to in all positions except one, i.e., we consider all single-element swaps with elements from (there are such sequences in total if we only do single element swaps). However, we can consider the top-k best and then compute for each one of them and select the one with the smallest . Then we repeat.
Code
Here’s a practical example with a convex loss and the minimum at (if we are only optimizing instead of ). To keep things simple, we will assume and , but this is without losing any of the generality. 3
import mlx.core as mlxc
VOCAB_SIZE = 10000
D = 4
CRITICAL = 0
vocab = list(range(VOCAB_SIZE))
embd = mlxc.random.normal([VOCAB_SIZE, D])
def f(x: int | list[int]) -> mlxc.array:
if isinstance(x, int) and x == CRITICAL:
return mlxc.zeros(D)
if isinstance(x, list):
elems = []
for el in x:
if el == CRITICAL:
elems.append(mlxc.zeros(D))
else:
elems.append(embd[el])
return mlxc.stack(elems, axis=0)
raise ValueError("Input must be an int or a list of ints")
def g(x: mlxc.array) -> mlxc.array:
return mlxc.sum(x**2)
# function to minimize
def G(x: int | list[int]) -> mlxc.array:
return g(f(x))
grad_g = mlxc.grad(g)
seq = [0,10] # initial sequence
SEQ_LEN = len(seq)
print("Initial sequence:", seq)
print("Initial loss:", G(seq))
NITER = 100
TOPK = 10
best_loss = [G(seq)]
available_embds = embd[vocab]
for _ in range(NITER):
grad = -grad_g(f(seq))
candidates = []
losses = []
for i in range(SEQ_LEN):
grad_i = grad[i]
# scan the embedding matrix for promising swaps
similarities = mlxc.sum(grad_i * available_embds, axis=-1)
similarities /= mlxc.linalg.norm(grad_i) * mlxc.linalg.norm(available_embds, axis=-1)
topk_indices = mlxc.argsort(similarities)[-TOPK:]
for idx in topk_indices:
candidate = seq.copy()
candidate[i] = int(idx)
candidates.append(candidate)
losses.append(float(G(candidate)))
best_idx = min(range(len(losses)), key=lambda j: losses[j])
seq = candidates[best_idx]
best_loss.append(losses[best_idx])
import matplotlib.pyplot as plt
plt.plot(best_loss)
plt.xlabel("Iteration")
plt.ylabel("Best loss")
plt.title("Best loss over iterations")
plt.show()
print("Best sequence:", seq)
print(f'Final loss: {best_loss[-1]}')
This does reduce the loss, though in typical coordinate-descent fashion it can get stuck. 😬
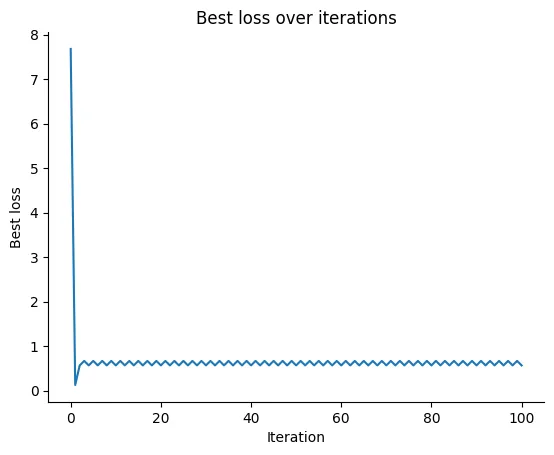
The trajectory depends on the available directions in . In the above plot, the algorithm stopped at [9998, 6304] with a final loss of 0.56.
To recap: We want to optimize , but lives on a large finite space and we can’t use gradients directly. However, because of the decomposition we can use the gradient instead as a proxy, then do a linear scan to find the closest viable update within .
Language models
For language models, is a map from token-sequence spaces to some hidden representation and maps the representation to the final loss value (as used in past works1).
Someone may ask: what if we instead insert a new symbol in and extend so that matches what the gradient expects? This then leads to methods like soft-prompting4 / prefix-tuning5.
Footnotes
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J.Z. and Fredrikson, M., 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043. Also read Shin, T., Razeghi, Y., Logan IV, R.L., Wallace, E. and Singh, S., 2020. ~AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts~.↩
Frank, M. and Wolfe, P., 1956. ~An algorithm for quadratic programming~ — the original optimization method that solves linear subproblems when navigating.↩
Math people need to add this disclaimer, don’t ask me.↩
https://huggingface.co/docs/peft/en/conceptual_guides/prompting↩
https://arxiv.org/html/2504.02144v1↩