GPT-2's Anisotropic Antics
This post explores GPT-2 hidden-layer anisotropy, drawing from the in-depth study by Ethayarajh (EMNLP-IJCNLP 2019). I wanted to reproduce some of this work for a while.
While this exploration focuses on GPT-2 anisotropy, the underlying motivation stems from observing similar phenomena in larger models like mistral-7B-v0.1.
In this post, I show a few quick examples of how anisotropy manifests.
What is anisotropy?
Anisotropy refers to the extent to which hidden token representations cover their respective vector spaces. For a given layer, if random tokens have representations that are uniformly distributed in direction, the representations are considered isotropic. Otherwise, they are anisotropic, the representations only cover a small cone in their space.
Let's make this clearer with an example. Suppose we take the sentences
text_a = "We can of course go beyond mere speculation of evolutionary change."
text_b = "Cooking mushrooms in a pot is hard."
We now pass them through GPT-2 separately and collect all activations per layer. GPT-2 has 12 layers + an embedding layer. We average over the sequence length and get 13 pairs of pooled tensors (each pair from each sentence, each tensor is ).
Compare the cosine similarity of the pooled tensors per layer:
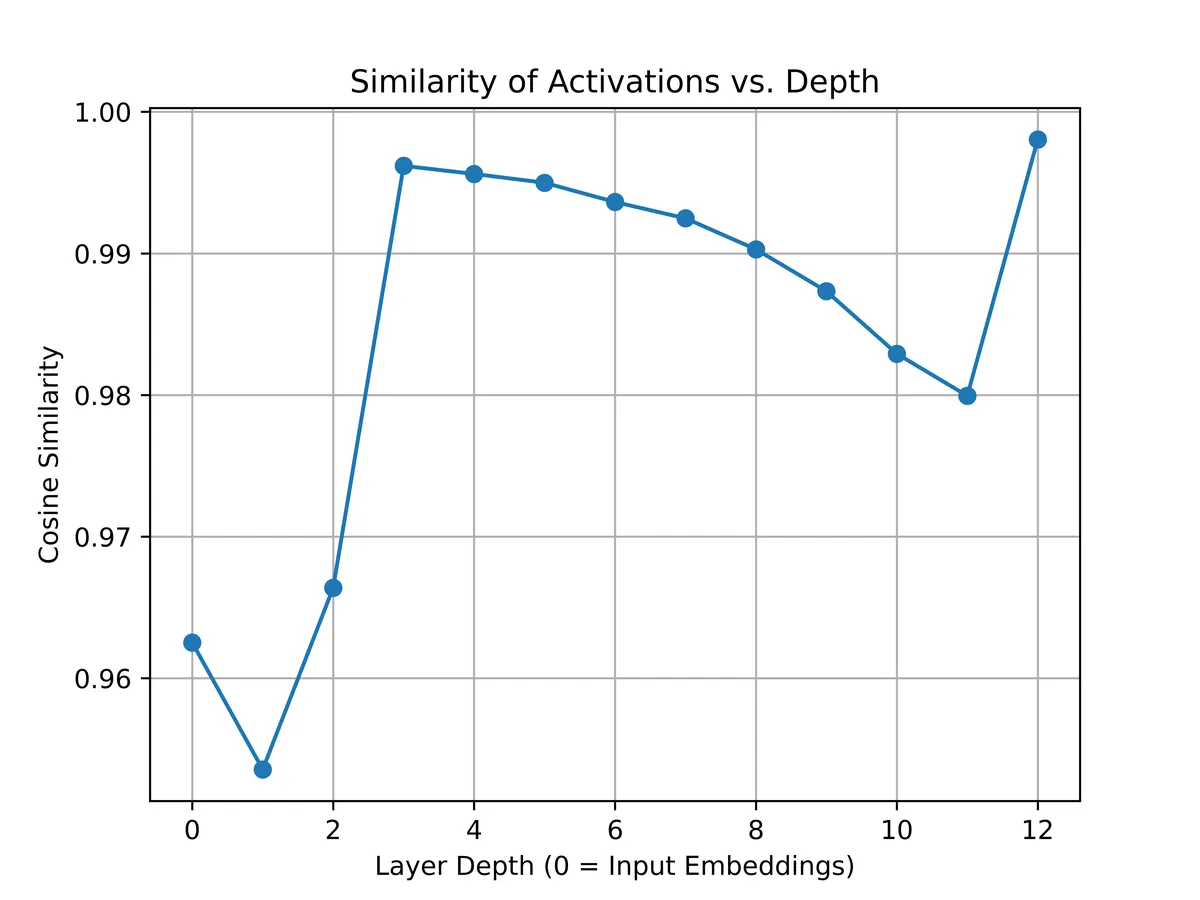
The similarity in each layer is usually above 0.96, reaching 0.9980 in the last layer! The pooled representations are basically pointing the same way!
It doesn't even matter if the sentences make sense! For example, compare:
text_a = "abcdef"
text_b = "Cooking mushrooms in a pot is hard."
and the same process would give:
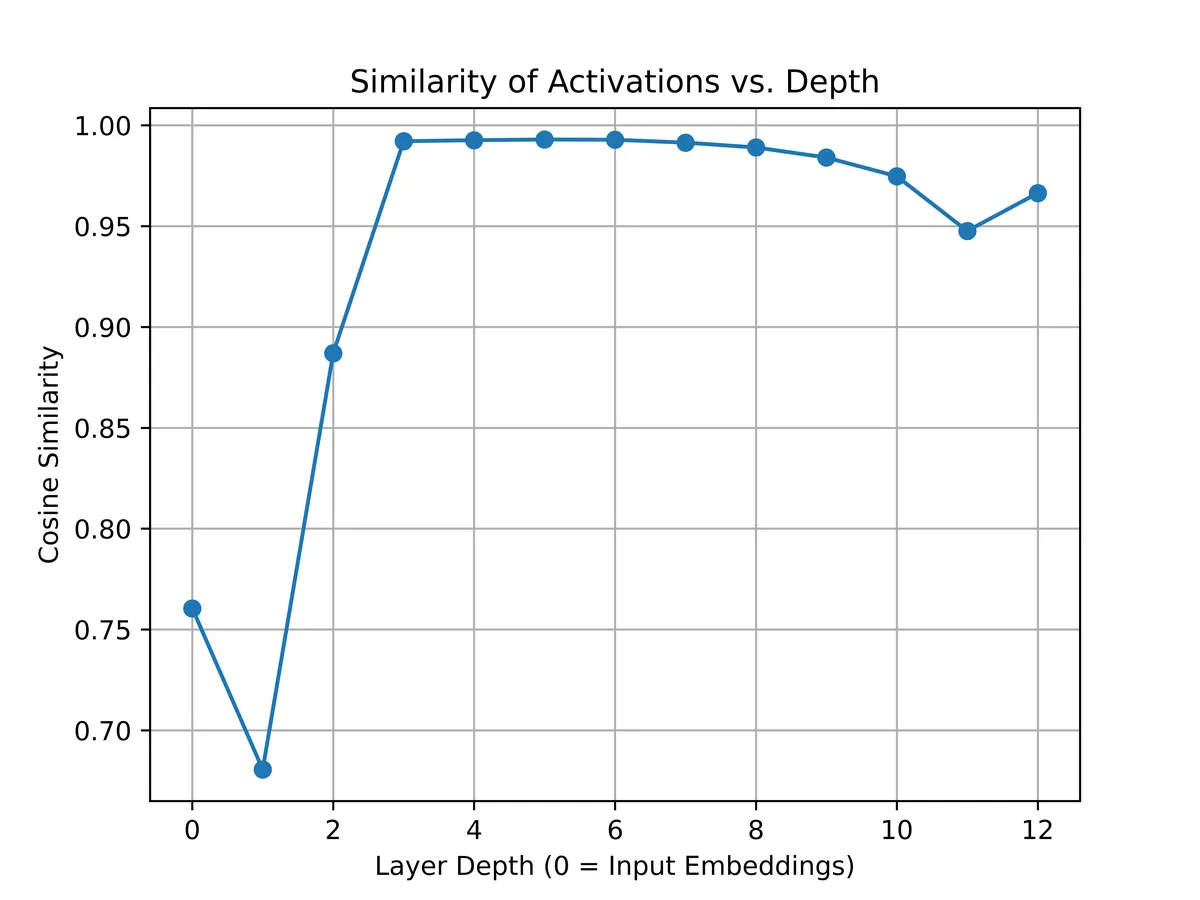
even more similar than before.
Comparing representations of tokens at the final hidden layer
We can also compare the similarity of representations of different tokens of the same sentence. Just pass the sentence through GPT-2, get the token representations from the final hidden layer, and compare their cosine similarity.
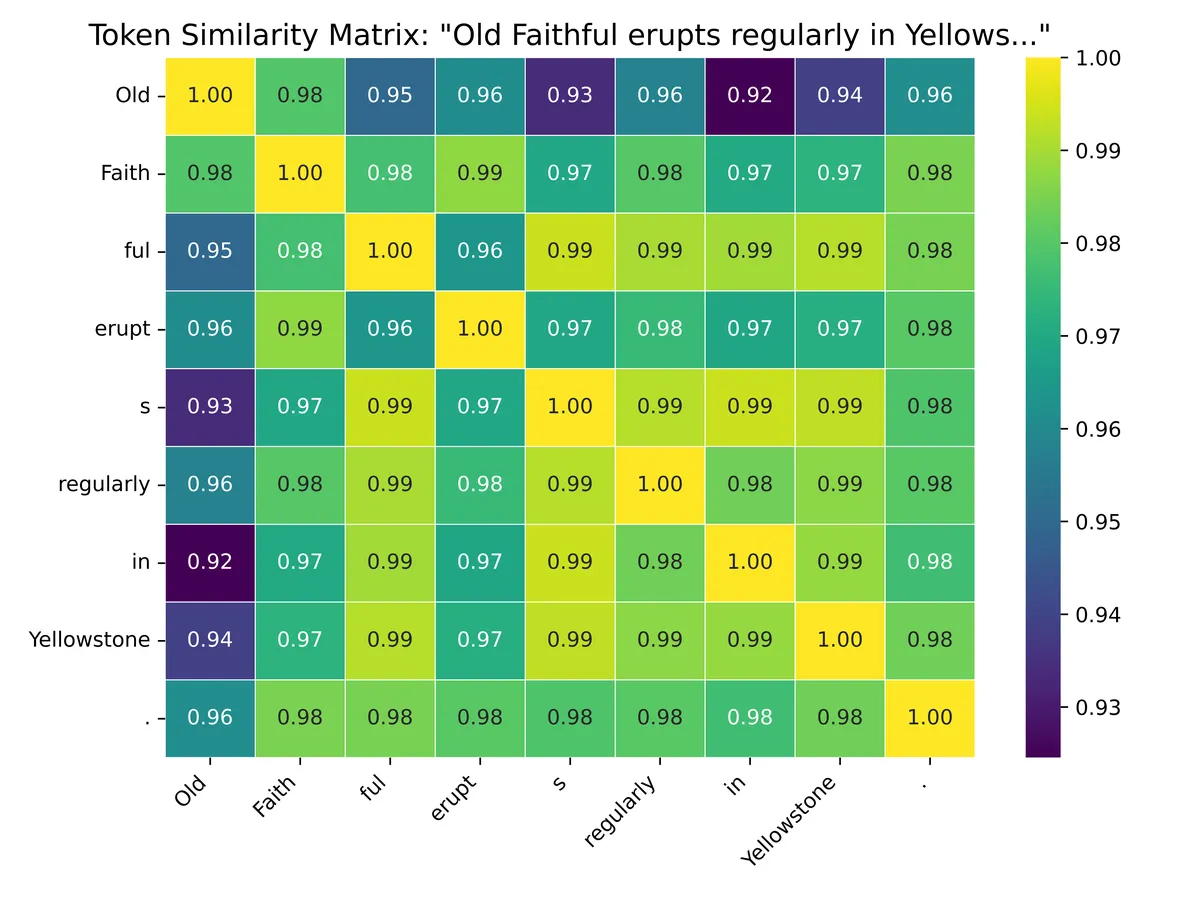
So, all the tokens have very similar representations as far as direction goes (smallest similarity is 0.92).
This does not mean we can get rid of the “cone” by collapsing it to a fixed unit direction with a variable, input-dependent, magnitude. Those small directional differences still hold important info for generating text.