Fun with stochastic activations
This post is inspired by a paper written by Maria Lomeli and coauthors at FAIR, the Ecole Normale Supérieure Paris Saclay, and Paris Cité University; see Stochastic Activation Functions
Gist of paper
Similar to how dropout, LayerDrop, etc., pick parts of a feedforward network and change those during training to increase robustness, stochastic activations switch between different activation functions, e.g., ReLU and SILU. This forces the network to be robust to using either activation. SILU allows for more gradient info to pass through, so convergence looks better, whereas ReLU induces sparsity which can be used for faster inference at test time.
The authors focus on LLM tuning, and specifically the feed-forward networks in the LLM. Two strategies are considered:
- Train with SILU for some time and with ReLU for some time, then switch to ReLU at test time.
- Or train with a stochastic activation that flips between the two during training and testing.
For reference, ReLU is defined as whereas SILU is , where .
Thoughts
There are a lot of nice questions here!
- What happens if we gradually move from one activation to the other instead of flipping?
- How often should we switch?
- What if we optimize the switch parameters according to input?!
- Dropout provides a picture of training multiple neural networks that share parameters and Bayesian dropout allows us to use this picture to estimate uncertainty. Can we do something similar here? -- I'll leave this for a different post.
I don't have the capacity right now to investigate those questions for LLMs, so instead I set up a simple classification problem with a small FFN.
I'll compare the following activations, using them for both training and testing as they are.
- ReLU
- SILU
- stoch: that's the stochastic activation from the paper with probability of switching set to 0.5. However, for simplicity, I sample ReLU or SILU per element regardless of whether it is positive or negative.
I also added two more activations into the mix!
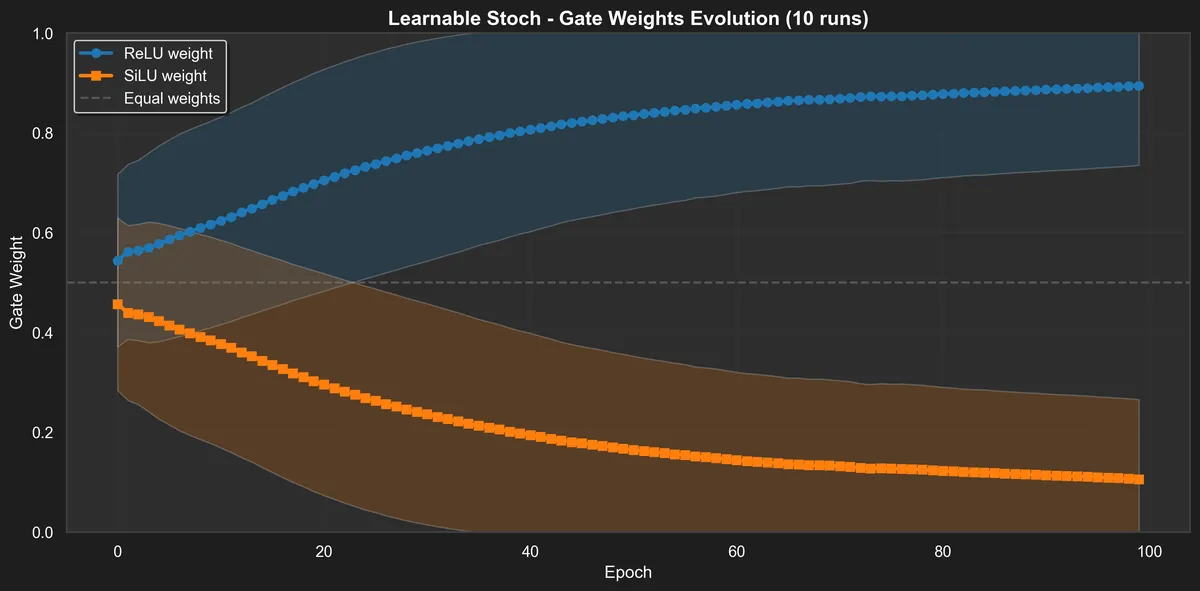
learnable_stoch: This doesn't switch between the two per se, instead we do a continuous mixture: , and , represented by a small neural net. This probably won't give us any sparsity, it only adapts the behavior of the activation when (as SILU and ReLU match for ).
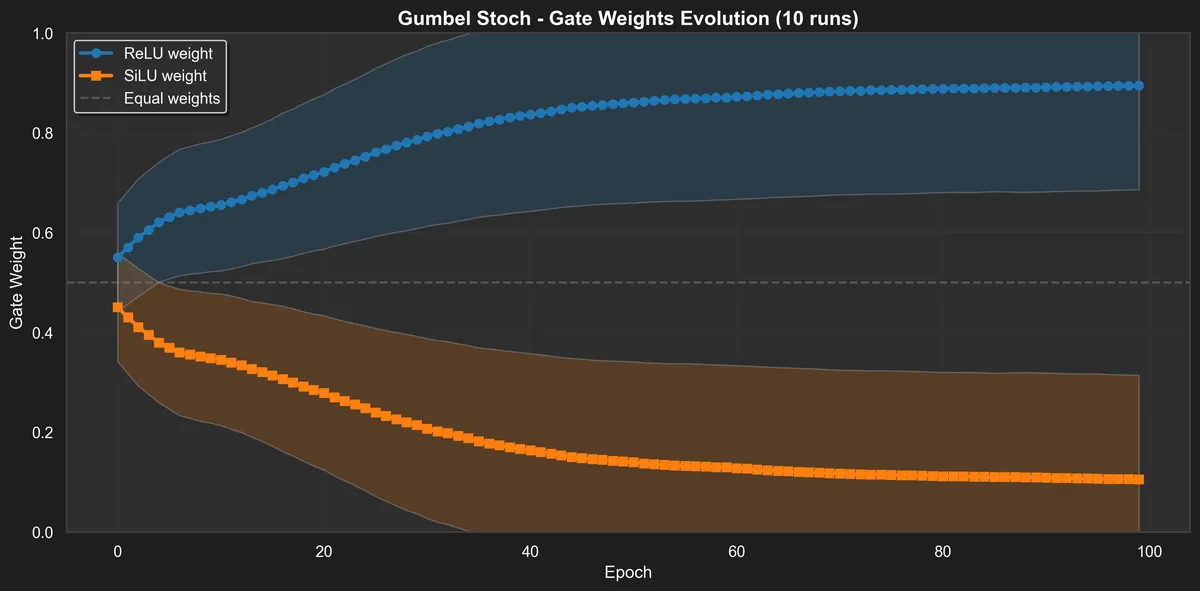
gumbel_stoch: This is like stoch, i.e., we sample activations, but instead of having a fixed , we learn a little by using the Gumbel-softmax trick. This way we still get some trackable sparsity because we will still use either ReLU or SILU.
Setup
You can find the code here. To reproduce my run, use
uv run python stoch_activation.py --epochs 100 --plots --lr 0.001 --n_clas
ses 2 --n_features 30 --n_layers 4 --n_samples 5000 --n_runs 10 --n_workers 10
Data
I generate synthetic classification data with sklearn.make_classification.
- Samples: 5,000
- Features: 30 (all informative)
- Classes: 2
I split 80/20 into train/test with a fixed random seed, and wrap tensors in PyTorch DataLoaders (batch size 128, shuffling on train).
Model
A fully-connected network with a narrow bottleneck:
After each hidden linear layer we apply a pluggable activation. Training uses cross-entropy on logits.
I use 4 layers for the experiment here, just so I can get more chances for the activations to do their thing.
Training and Metrics
- Optimizer: Adam with learning rate
lr=0.001and weight decay set to0.01 - Epochs: 100
Those are reported per epoch:
- Loss: mean cross-entropy on the validation loader each epoch.
- Sparsity: fraction of post-activation elements with magnitude measured on the first hidden layer on the validation data.
Results
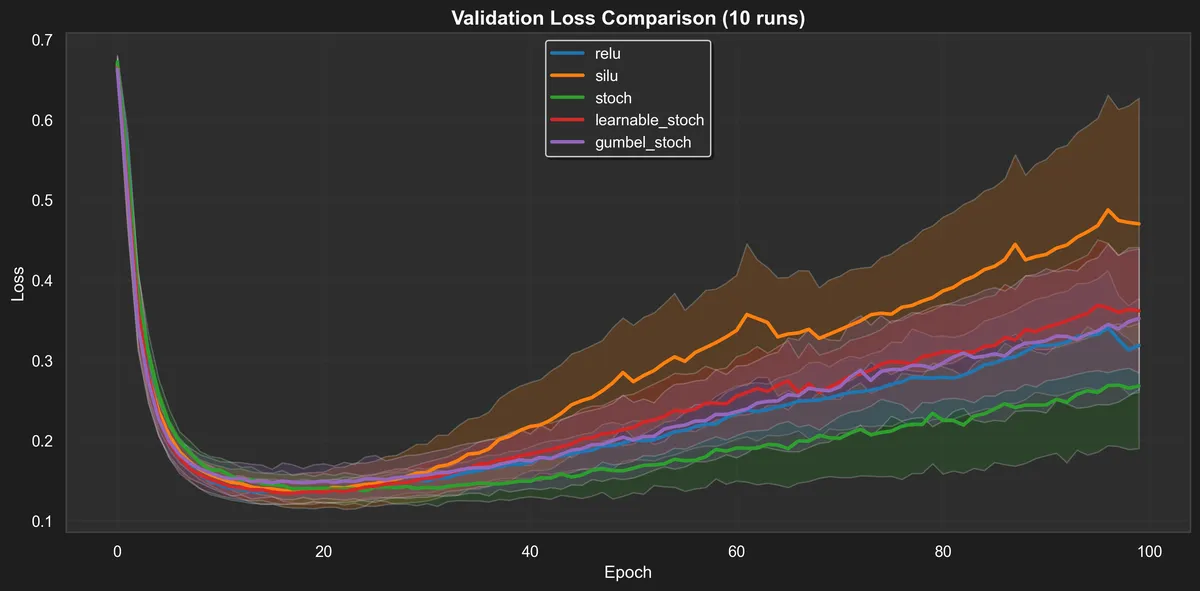
All metrics are reported as averages over the ten runs, with std intervals. This is still a small experiment, but we can see some interesting behaviors.
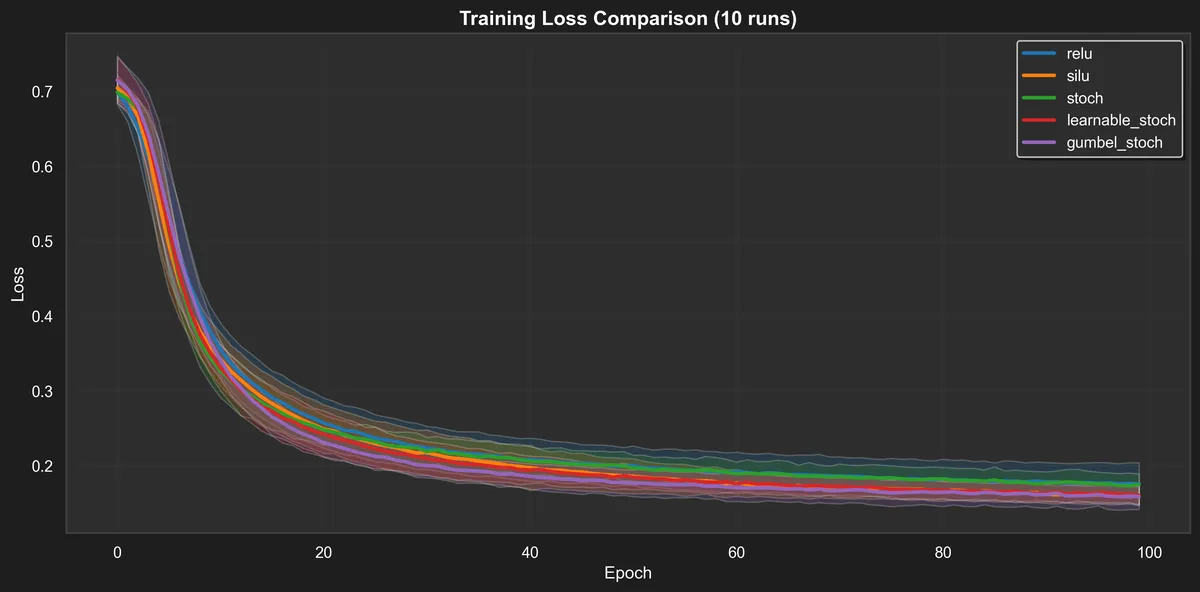
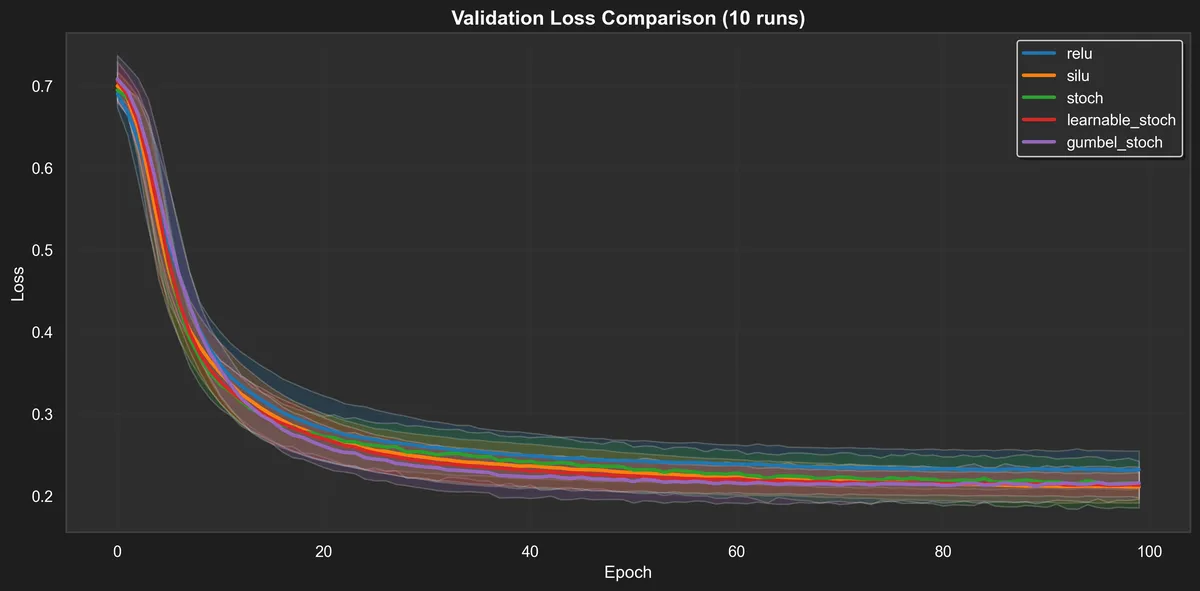
Training loss is unremarkable, but we can see some rough ordering and the picture for the validation loss is similar.
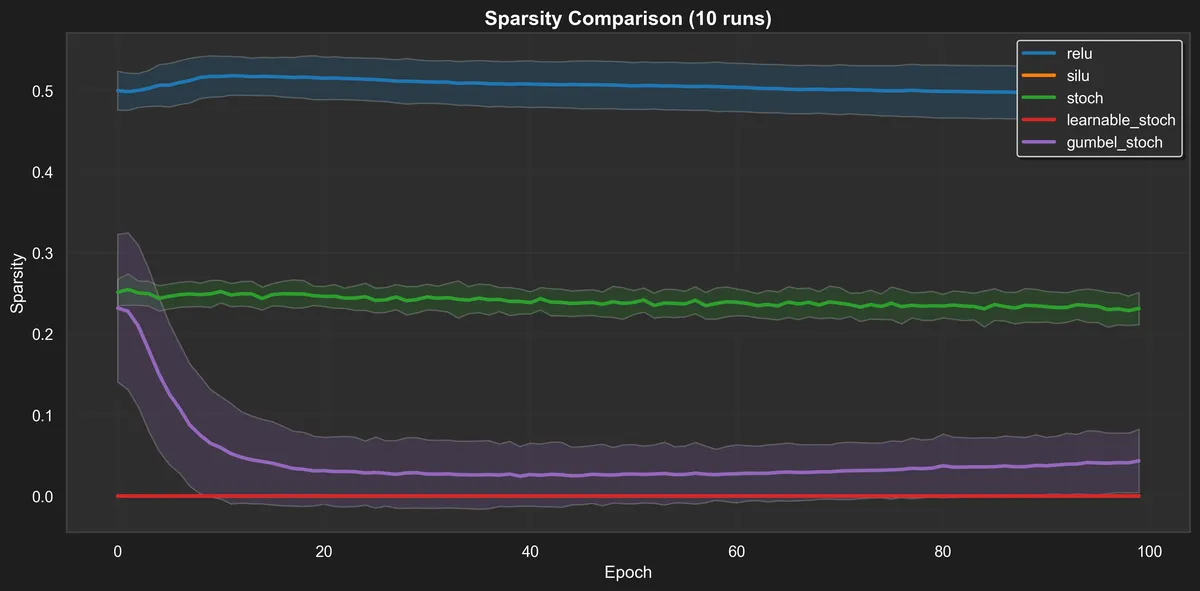
Sparsity over time on the validation set. It aligns with expectations:
- relu: about half of the activations are small throughout training.
- stoch: should be in-between SILU and relu, and that matches to 25%.
- learnable_stoch: as this is a mixture, we don't really get tiny activations.
- gumbel_stoch: starts sparse and close to stoch, but settles to a much smaller fraction.
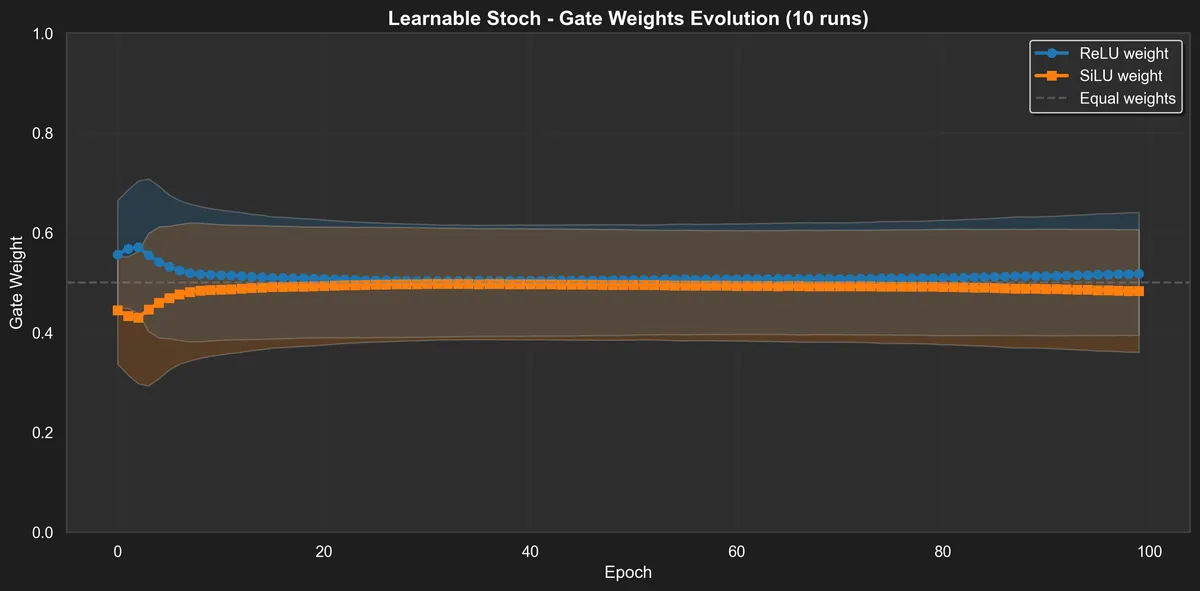
We can see those pictures by also checking the distribution of the "gates" for learnable_stoch and gumbel_stoch.
The learnable stochastic gate quickly converges to an even 0.5–0.5 mix of ReLU and SiLU. Since the gating network only really has something to decide when (both activations behave the same for ), this makes sense.
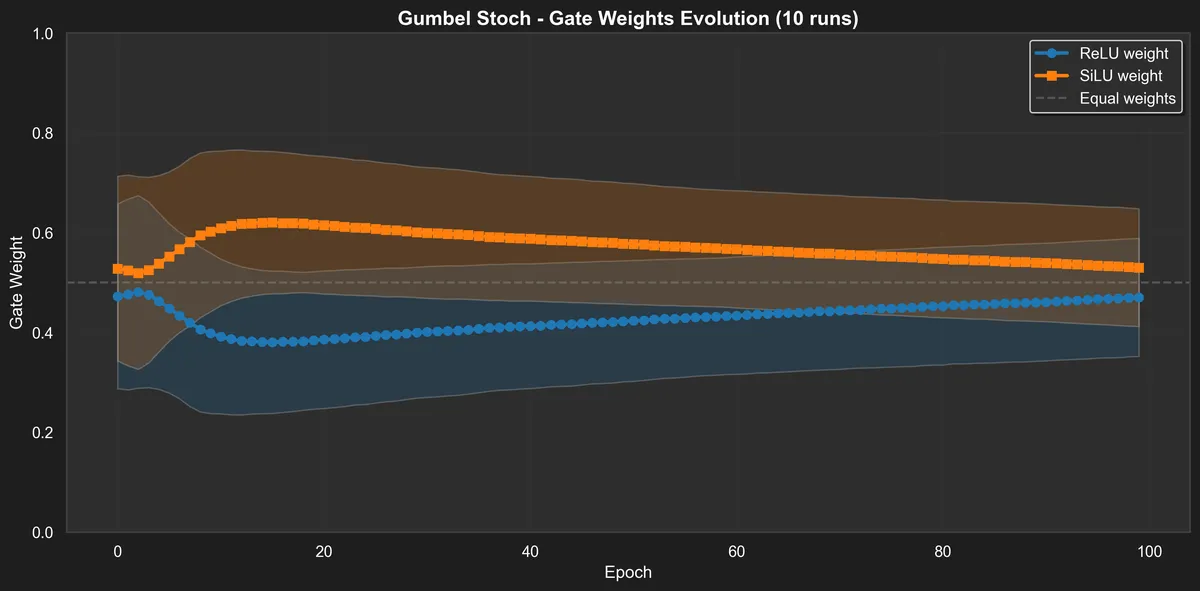
Dynamics of gumbel stoch are a bit more interesting! There is short term preference for SILU and then we equilibrate. I guess if we have to select one to use between the two, it would make the most difference to pick SILU in the beginning of the loss descent.
Other behaviors
Surprisingly, if we make the model large enough to overfit, the dynamics of the learned activations change and there is a strong preference for ReLU. Here's what happens if we set the bottleneck dimension from 4 to 16.