A few notes on directed information
TL;DR: Notes on directed information, inspired from the use of directed information in Abel, David et al. “Plasticity as the Mirror of Empowerment.” ArXiv abs/2505.10361 (2025) – I want to eventually write some notes on this work as well.
Mutual Information
Quick recap of mutual information, for more see the wiki.
Suppose we have random variables with values over some space . Then, the mutual information (MI) captures, on average, how much information we learn about if we observe . MI is defined as
Note the tension between the joint and the marginal product .
There are lots of useful relationships around , but here I’ll only mention a few:
- Symmetry: .Because of symmetry, there is no notion of causality or time in MI.
- Non-negativity: .
- Expressing in terms of entropy / relative entropy: .
From 3., we can also get that if X and Y are independent, then , i.e., there’s no information to be learnt from about . On the other side, if, for example, , then , so , i.e., we have learned all there is to know.
Directed Information
To introduce directed information, we will use notation from the original paper by Massey, 19901.
For , , each component being a discrete random variable. Values of those will be denoted by . We use square brackets to denote that those objects are sequences of random variables.
In the original work1, Massey was studying the behavior of a discrete channel with input (X) and output (Y) random variables. One can make all sorts of assumptions on how an input variable affects the corresponding output variable . For example, we can assume that , then , (arrows here denote dependence) and so forth, each generation being independent of the previous one.
A bit more interesting is to assume that each output variable plays a role into the generation of the next one, the DAG looking something like this:
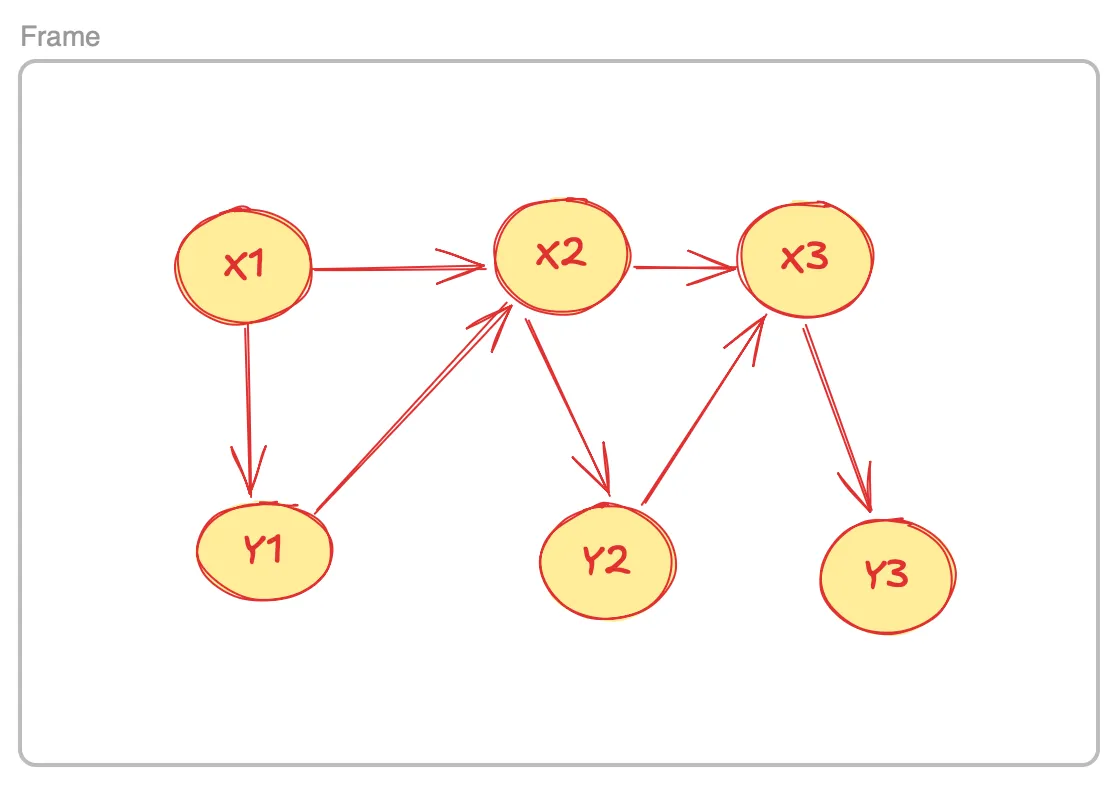
How much information do we get about if we know ? We could try to answer this question with , but this is a symmetric quantity and doesn’t take into account the order the variables enter the picture.
This is where directed information (DI) can help:
Here is regular conditional MI. DI captures how information flows through the channel, from input to output.
There are a few nice properties of DI as well, here are some I liked:
- : this asymmetry is characteristic of DI. For example, one can show it by considering and and .
- : each term of the DI sum contains the partial sequence and replacing by the full sequence can only increase mutual information, which then gives the result (by means of a telescopic sum). Equality holds when there is no feedback from output back to input.
- Conservation of information! , note that the second term starts from . Mutual information captures both the forward and the backward flow of information, hence the symmetry.
Proving conservation of information (sketch)
There are various ways to show 3 for DI. For example, for an appropriate definition of conditional entropy (called causally conditioned entropy), we get an equivalent formula to MI’s 3:
Then it is sufficient to show that
which requires the decomposition rule for causal conditioning (denoted by )
and the definition of joint entropy as
The term
The backward can be interpreted as the strength of feedback: how much past outputs influence future inputs.
Generalized Directed Information
To handle causal interactions that may begin or end at different times, we can generalize Massey’s directed information to arbitrary causal windows. Following Abel et al. (2025), the Generalized Directed Information (GDI) between sequences and is defined as
This quantity measures how much information flows from the segment into the segment , respecting the causal structure of the process. When and , it reduces to Massey’s original directed information .
GDI also satisfies an entropy–difference identity, sometimes called the Kramer Decomposition:
This form generalizes the standard relation , extending it to arbitrary causal intervals.
Massey, J. (1990, November). Causality, feedback and directed information. In Proc. Int. Symp. Inf. Theory Applic.(ISITA-90) (Vol. 2, p. 1).↩